

ICASSP 2023 参加レポート

2020 年に新卒で PKSHA Technology に入社した、アルゴリズムエンジニアの呉です。今年の 6 月 4 日から 10 日の一週間にわたって、ギリシャのロードス島で開催された世界最大の信号処理の国際学術会議 ICASSP 2023 に参加し、画像認識の汎用モジュール gSwin について現地でポスター発表を行いました。この記事では、学会を通じて私が得たこと・感じたことについて書きたいと思います。
呉孟超 | AI Solution事業本部 アルゴリズムエンジニア
東京大学大学院理学系研究科博士課程において素粒子理論の研究に従事。その後、PKSHA Technology参画。 動画像案件、クレジットカードの不正検知案件等でアルゴリズムの開発を担当した経験を持ち、 動画像領域、予測・最適化領域、自然言語処理等、様々な技術領域に精通。博士(理学)。
ICASSP 投稿の経緯
アルゴリズムエンジニアとしてのメインの仕事は、基本的にはアルゴリズムをクライアントに提供することですが、新卒 2 年目あたりに、クライアント横断で利用可能な画像認識モジュールの内製開発を担当することになりました。十分な品質で開発を終えたあとも改善に取り組んでおり、gSwin はその一環で生まれました。
最初は最新の技術をキャッチアップし実装する活動をしておりましたが、その過程で新たなモデルの種を着想し、社内の計算リソースをフル活用して実験を回し、ついには小サイズで高精度なモデルを実現可能であると確信しました。学術的に意味のある成果が得られたと判断し、全世界の研究者に共有することで少しでも画像認識分野の発展に貢献できるようにという思いで、国際学会に投稿することにしました。
ICASSP 2023 について
国際学術会議 ICASSP (International Conference on Acoustics, Speech, and Signal Processing) は IEEE SPS (Signal Processing Society) のフラグシップ会議で、信号処理に関する学術会議では世界でも最大規模です。信号処理に関連する、音声、音響、言語、画像、機械学習、医用画像、通信などの幅広い分野を扱っています。例年約 1500 本の論文が採択されますが、今年は投稿自体が大きく増えて 2500 本程度が採択されました。
1976 年に第 1 回の ICASSP がフィラデルフィアで開催されてから今回で 48 回目の開催で、去年はシンガポール、今年はギリシャのロードス島で開催されました。来年は韓国で開催予定です。 去年まではオンラインと現地のハイブリッドでしたが、今年は基本的に現地開催でした。

300 以上のセッションが詰め込まれた非常に濃密な学会で、ポスターセッション 13 個、オーラルセッション 9 個がほぼ常に同時に開かれていました。参加者も多く、3700 人以上が現地参加したとのことで、ポスター会場は熱気を感じるほど賑わっていました。

ロードス島はエーゲ海に位置する、美しい自然と歴史的な魅力を持つ島です。透き通った青い海と美しいビーチが島を囲んでいて、開催期間には海で泳ぐ人もいました。地中海の交差点にあたるこの島には長い歴史があり、例えばユネスコの世界遺産にも登録されている中世都市には、城壁に囲まれた狭い石畳の通りが迷路のように広がっています。

余談ですが、ICASSP Cat Challenge という 公式のイベント が開かれるほど、ロードス島にはたくさんのネコがいます。

論文の解説
gSwin は Swin Transformer と gMLP という 2 つの画像認識モデルをもとに構築されたモデルです。いずれも ViT の派生と考えられますが、まずは派生元の ViT について簡単に説明します。
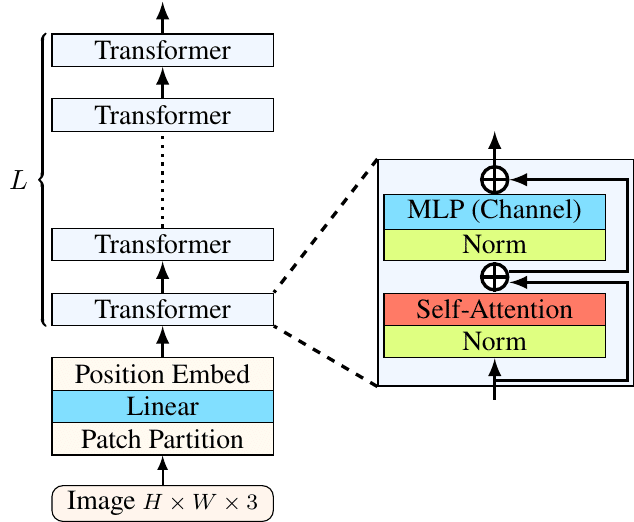
ViT は、自然言語処理の分野で誕生した Transformer (GPT 等にも使われています) を初めて画像分野に用いたモデルです。画像を小さなパッチに切り分けたものをトークンとみなし、あとは普通の Transformer と同様に処理するシンプルなモデルです。CNN が当たり前だった CV 領域において、Attention 機構のみで SOTA を塗り替えた衝撃は大きく、ViT の誕生を皮切りに数多くの Transformer モデルが CV で提案されました。その中でも重要なモデルが Swin Transformer で、局所性、階層構造など、ViT では考慮されなかった画像特有の特徴を踏まえた Transformer モデルであり、比較的軽いモデルですが高い精度を達成しています。 近年の CV の論文でよく用いられていおり、ViT と並ぶデファクトスタンダードとなっています。

gMLP は ViT で使われている Attention 機構をより単純化しようとする研究で、ほぼ同時期に発表された 3 つの MLP 系モデル (あと 2 つは ResMLP、MLP-Mixer) の 1 つです。Attention 機構の代わりにより単純な SGU という機構を用いており、ViT と同等の精度を同等のモデルサイズで達成したということで話題になりました。画像特有の特徴である並進対称性をデータから学ぶ能力があることが示唆されています。MLP 系の研究は Transformer 系と比べてやや小さな盛り上がりではあるものの、現在も新しいモデルが提案されています。

gSwin は Swin Transformer と同様、gMLP に局所性、階層構造を組み込んだものです。いくつかの工夫が施されていることとSGU の軽量さによって、Swin Transformer より小さなモデルでありつつも同等以上の精度を達成しました。画像分類に限らず、物体検知、セグメンテーションといった主要な CV のタスクでも有効性が確認されており、Swin Transformer に代わる backbone モデルになりうるものと考えています。詳しくは論文をご一読ください。


学会で印象に残った発表
多くの興味深い発表に触れましたが、その中でも個人的に印象に残ったものを2つ紹介しようと思います。
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
画像生成 AI にもよく使われる CLIP は画像とテキストの埋め込み表現を揃えるものです。SpeechCLIP は画像、テキストに加え音声も同じ空間に埋め込むモデルで、これらはいずれも英語が対象です。この発表で提案された M-SpeechCLIP では、テキスト情報を使わずに直接多言語の音声と画像の埋め込み表現を揃えるモデルが提案されています。
ICASSP のメインテーマの 1 つである音声認識に画像、多言語という要素も足されており、AI 研究の潮流が感じられる興味深い研究でした。
Perspectives Talk I - Industry: Toward Integrative AI

Azure AI のトークです。テキストだけでなく、視覚・音声、多言語も重視する統合的AIの重要性を述べており、動画内の物体のCaptioningを行うデモ、音声認識と多言語への翻訳を続けて行うデモが披露されました。

人間の学習・理解に近い形でよりマルチモーダル・多言語学習を行う、未来のAIへの期待が感じられるトークでした。
おわりに
情報系の学会に参加するのは初めてでしたが、想像以上の規模感に圧倒され、とても有意義な経験になりました。かなり情報量が多く濃密な一週間で、幅広く最先端の機械学習技術に触れつつ、研究の最前線の議論を間近で見ることができ、多いに学びになりました。私自身は例えば音声認識関連には疎いのですが、学会を経て自分の幅も広がったと感じます。
PKSHA Technology では画像処理を含むアルゴリズムを社会に実装していく仲間を募集しています。AI関連の研究開発に従事されてきた方はもちろん、Kaggleなどのコンペティションに積極的に参加している方や、情報系以外のバックグラウンドから参画後に活躍している方など、多様なバックグラウンドを持つエンジニアが活躍しています。研究開発やコンペティションで育まれた技術を社会に還元することにご興味のある方は、是非ご応募ください!
▼ 25 新卒:アルゴリズムエンジニア(データサイエンティスト)本選考はこちら

▼ 25 新卒:アルゴリズムエンジニア(データサイエンティスト)インターンはこちら

▼採用職種一覧
▼カジュアル面談も受け付けています:Wantedlyはこちら