

RecSys Challenge 3 位入賞 & 現地参加報告

こんにちは、PKSHA Technology でアルゴリズムエンジニアをしている小川浩輝です。このたび、推薦システム分野におけるトップカンファンレンスである RecSys(The ACM Conference on Recommender Systems)が主催する RecSys Challenge に、弊社メンバー(岩井、富田、荒井、齊藤)と共に参加し 3 位入賞を達成しました。解法は論文にまとめ、2024 年 10 月 14 日 〜 10 月 18 日の間にイタリアのバーリで開催された RecSys 2024 にて発表を行っています。
本記事では、RecSys Challenge における弊社解法および現地参加した RecSys 2024 の様子を紹介したいと思います。
小川 浩輝(AI Solution 事業本部 アルゴリズムエンジニア)
慶應義塾大学経済学部にて、都市経済学を専攻。前職では機械学習エンジニアとして人材領域におけるデータ分析業務、自然言語処理を活用したレコメンドロジックの実装などを担当。その後、PKSHA Technology に参画。現在は金融業界・小売業界等多様な領域においてソリューション提案・実装を行う。PKSHA 内で 4 人目の Kaggle Competitions Grandmaster。
RecSys Challenge
タスク
EkstraBladet というデンマークのオンラインニュースサイトにおいて、次にクリックされる記事を予測するタスクでした。

特徴的な点は、「inview」というユーザーに表示された記事のリストが事前に与えられ、その中からクリックされた記事を予測するタスクだったことです。

推薦においては、多数のアイテムから推薦候補(= candidate)をまず絞り込み、その上で candidate をランキングづけして最終的な推薦アイテムを決める 2 段階推薦が行われることがありますが、今回のタスクでは candidate がすでに決められている状態でした。
データ
主に inview データおよびクリック履歴データが与えられました。
inview データおよびクリック履歴データは、訓練用(= training)・検証用(= validation)・テスト用(= test)それぞれ提供され、各データの時系列は以下のようになっていました。

各データ分割の inview データについて、時系列が重複しないようになっています。
評価指標
AUC(Area Under the Curve)や MRR(Mean Reciprocal Rank)、NDCG(Normalized Discounted Cumulative Gain)といった推薦領域でよく使われるいくつかの指標が用いられましたが、最終的な順位は AUC で決定されました。
解法紹介
弊社チームの解法の概要は以下のようになっています。

主に①特徴量エンジニアリング②アンサンブルを活用した推論の二つのパートに分かれます。
①特徴量エンジニアリング
今回のタスクに効果的に対処するため、私たちは特徴量エンジニアリングを5つのパートに分けて実施しました。
Article timeliness features
ニュース記事の新鮮度に関する特徴量群です。
特に「記事が発行されてどれくらいの時間が経ったか」という特徴量は非常に有効で、ニュース記事推薦においていかに記事の新鮮度が重要かがみて取れました。

2. Content based features
記事の内容を元にした特徴量群です。
inview に表示された記事の内容と、ユーザーが過去クリックした記事の内容の類似度などが該当します。記事の内容をベクトル化する様々なモデルで実験し、精度向上を図りました。

3. Collaborative filtering features
協調フィルタリングに関する特徴量群です。
ユーザーのクリック履歴を用いて学習した item2vec を使用して計算された、inview 内の記事とユーザーがクリックした記事の類似度などが該当します。

ただし、こちらの特徴量の貢献度は限定的でした。
理由として、「ニュース記事は入れ替わりが激しく、クリック履歴と inview に表示された記事のオーバーラップが限定的で、予測したい inview に表示された記事の embedding を十分に学習できていない」などが考えられそうです。
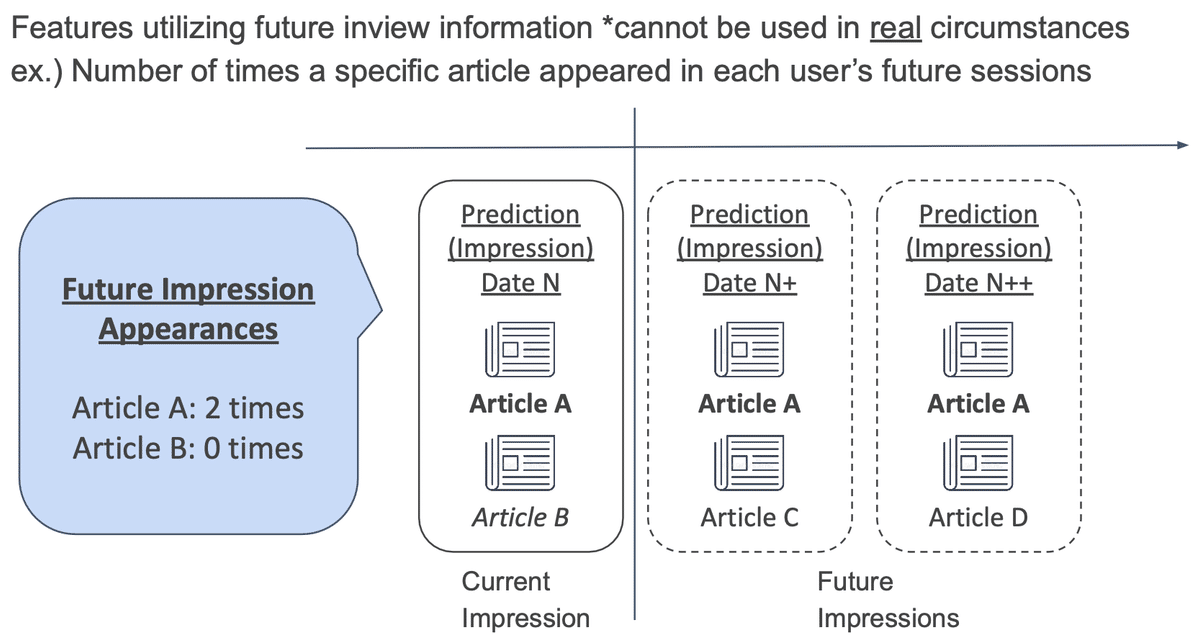
4. Leaky inview features
こちらは Leak を使用した特徴量群になります。
inview データは、訓練用・検証用・テスト用それぞれで 1 週間与えられます。この設定が今回のタスクにおいて Leak を発生させていました。例えば、6/1 のユーザー A の invew データに含まれる記事が、6/2 以降のユーザー A の inview データにも登場するかを知ることができてしまいます。ユーザーがクリックした記事は将来表示される可能性が低いなどの仮定が成り立つ場合は非常に有用な情報となります。
こちらの特徴量群は本 Leak を利用したものになり、例えば、将来のセッションで当該記事がユーザーに表示される回数などを特徴量化しました。
5. Miscellaneous techniques
その他の特徴量群になります。
inview の性質に基づき、inview 内の相対性を反映させた特徴量が特に有効でした。
例:inview 内でのランキング、inview 内の最大値に対する割合など

②アンサンブルを活用した推論
training、validation データセットをマージしたデータセットを作り、ランダムに抜き出したデータで学習させた LightGBM を 8 つ作成し、アンサンブルしています。データを増やすことによる計算量増加と精度向上のバランスを取るため、すべてのデータを一度に学習させず、全体の 10% のデータでの学習を 8 回行いました。(コンペ期間中、様々なアンサンブル方法を検証しましたが、今回のやり方が最も高い精度でした。)
結果
145 チーム中 3 位となり、入賞することができました!
今回の RecSys Challenge は、世界最大のデータサイエンスコンペティションプラットフォームである Kaggle でも上位の成績を残している方々が多く参戦しており、終盤は特にスコア競争が激しかったです。
そのような激戦の中で 3 位に食い込めたことはとても嬉しく、日頃の研鑽の結果を国際的な舞台でも示すことができたのではないかと感じています。

RecSys 2024
RecSys Challenge にて無事 3 位に入賞したため、解法を論文にまとめ、イタリアのバーリで開催された RecSys 2024 にて発表を行いました。

RecSys 2024 は初日と最終日に workshop が開催され、中 3 日がメイントラックとなっていました。弊社発表は初日の workshop にて実施しました。
弊社発表
RecSys 2024 初日の workshop にて、チームメンバーの岩井・富田により発表が行われました。質疑応答では「特徴量の重要度をどのように算出したか」「協調フィルタリング系の特徴量の重要度が低い理由は?」など活発な議論が交わされました。

workshop の中では、1 位・2 位の解法も紹介されました。
1 位や 2 位のチームの共通点として、Transformer 等の時系列データを処理することができるニューラルネットワークを活用している点が挙げられます。
テーブルデータのタスクでは LightGBM などの勾配ブースティングモデルが使われることが多いですが、時系列性の強いデータについては Transformer 等の時系列を考慮できるモデルを選択肢として入れておくことは大切に感じました。
他にも RecSys Challenge に関連する論文の発表が行われ、非常に学びの多い workshop でした。
メイントラック
workshop の翌日から 3 日間にわたり、豪華な会場でメイントラックが開催され、弊社メンバーも参加いたしました。

メイントラックのセッションは以下画像に掲載された 12 種類ありました。

Cold Start や Collaborative Filtering など推薦に関係する昔ながらのセッションだけでなく、近年注目が集まっている LLM(Large Language Model)× 推薦に関するセッションもありました。LLM に関するセッションは 2 パート存在したり(他のセッションについては 1 パートのみのものもあった)、他のセッションの中でも LLM を用いた論文が発表されたりと、推薦システム分野についても LLM を用いた研究が活発に行われている印象を持ちました。
その他、メイントラックでは産業界からの発表が多かったのが特色で、特に Netflix による検索と推薦、どちらも実行可能なフレームワークの紹介などは興味深かったです。
ポスター発表
RecSys 期間中は、Lunch Time や 1 日に 2 回程度あった Coffee Break の時間の中でポスター発表を回ることができました。
こちらでも企業からの発表は多く、各社の推薦周りの取り組みを知ることができ、とても学びが大きかったです。

おわりに
RecSys Challenge への参加を通じて、ニュース推薦特有の傾向(記事の新鮮度の重要性や協調フィルタリング適用の難しさなど)やニュース推薦に適した手法などを学ぶことができ、とても有意義でした。
学んだ手法については、ニュース推薦に限らず適用できそうなものもあったため、得た知見については実際のプロジェクトの中でも積極的に活用していきたいと思いました。
また、RecSys のメイントラックやポスター発表では、推薦に強みを持つ企業群の知見などが幅広く提供され、推薦分野における最新動向をつかむ上で非常に効果的であると感じました。得られた学びを活かして、より実用的で価値のあるアルゴリズムを様々なプロジェクトの中で社会実装していきたいと考えております。
―INFORMATION―
PKSHA Technology では推薦に限らず様々なタスクにおいて AI の社会実装を進めており、共に社会実装を加速させる仲間を募集しています!採用サイトや Wantedly から応募が可能ですので、是非ご覧ください!カジュアル面談も大歓迎です!
▼ アルゴリズムエンジニア【26 新卒】


▼アルゴリズムエンジニア【中途採用】
▼カジュアル面談も受付中です!Wantedly はこちら