

Python の 並列/並行処理 の比較

こんにちは。PKSHA Technology の AI Solution 事業本部にてソフトウェアエンジニアを務めている加藤と申します。先日インタビュー記事が出ましたので、こちらも併せてご覧ください。
本記事では、Python での並列/並行処理の初歩について紹介いたします。Python は、機械学習ライブラリの豊富さから、非常に多くのプロジェクトで利用されるようになっています。この言語を使いこなせることは、機械学習を行う上で重要なファクターとなります。Python は言語仕様および歴史的経緯から GIL と呼ばれるスレッドによる並列処理を阻害する仕組みが導入されており、他のプログラミング言語と比較してスレッドによる並列処理の性能向上が処理内容によって大きく異なります。
以下の記事では、はじめに Python の並列処理の標準ライブラリである、 threading と multiprocessing についてそれらの特徴について述べます。その後、並行処理の標準ライブラリである、 asyncio との比較を行います。先に結果の概要を記載しますと、以下の通りとなります。

スレッド と プロセス
threading と multiprocessing という単語は、コンピューターサイエンスの用語のスレッドとプロセスから来ていると考えられるため、以下で不正確ながら簡単に説明します。詳細は Wikipedia の記事などをご参照ください。
プロセス
オペレーティングシステム(以下、「OS」)のリソース管理の単位です。あるプロセスがオープンしたリソース(例えば、メモリやファイル)は、他のプロセスからその内部状態を読み書きすることは、基本的にできません。
スレッド
プログラムの実行の単位です。手続き型プログラミング言語では、基本的に命令列の順に実行されますが、その実行の流れのようなものです。プロセスには、1 つ以上のスレッドが存在しており、その全てで同じリソース(例えば、メモリやファイル)の内部状態を読み書きすることができます。OS はこのスレッドの実行を時間的に区切って、なるべく公平に CPU 上で実行させます。threading では異なるスレッドを用いて並列実行を行い、multiprocessing では異なるプロセスを用いて並列実行を行います。
concurrent.futures モジュール
以下のコードでは、直接 threading と multiprocessing を利用せず、 concurrent.futures を利用して説明します。そのため、先にこのライブラリについて説明します。
concurrent.futures モジュールは、並列処理のデザインパターンの一つである Future パターンを実装したライブラリです。このモジュールでは、threading または multiprocessing を利用し、スレッドプールまたはプロセスプールを作成し、そのプール内で処理を実行します。利用の際は、 Executor 抽象クラスを実装した、ThreadPoolExecutor または ProcessPoolExecutor を利用し行います。各々のクラスは、名前の通り、各々スレッドとプロセスによる並列化に対応します。
*Executor 作成時の max_workers と、利用できる CPU 数の小さい数値が、最大並列度となります。SMT については考えないこととします。
実測
Python におけるスレッドとプロセスの並列化の差を明らかにするために、差が出やすいベンチマークを行い実測をします。ベンチマークを行ったマシンの構成は以下の通りです。
OS: macOS Sonoma 14.2.1
Model: M1 Macbook Air
SoC: Apple M1 8コアCPU 8コアGPU
Memory: 8GB
Python: Python 3.10.12 (brew でインストール)パターン1: CPU処理
初めに CPU 処理が重たいケースでベンチマークとして、以下のコードを利用します。以下のコードでは、 n 回 (x^(2^y)) / (x^(2^y)) を愚直に計算します。
コード
import time
from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from typing import List
def too_slow_function(x: int, y: int) -> int:
# x^(2^y) を計算
for _ in range(y):
x *= x
return x
def too_slow_function2(x: int, y: int) -> int:
# 1 を計算
return too_slow_function(x, y) // too_slow_function(x, y)
def _main() -> None:
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
parser.add_argument("-x", type=int, default=2)
parser.add_argument("-y", type=int, default=30)
parser.add_argument("-n", type=int, default=3)
parser.add_argument("--max-workers", type=int, default=5)
parser.add_argument("--executor", choices=["process", "thread"], default="process")
args = parser.parse_args()
x_list: List[int] = [args.x] * args.n
y_list: List[int] = [args.y] * args.n
max_workers: int = args.max_workers
executor_class = (
ProcessPoolExecutor if args.executor == "process" else ThreadPoolExecutor
)
with executor_class(max_workers=max_workers) as executor:
start = time.time()
futures = executor.map(too_slow_function2, x_list, y_list)
for res in futures:
print(res)
end = time.time()
print(f"elapsed: {end - start:.3f} sec")
if __name__ == "__main__":
_main()結果
x=2, y=30 の時(CPU処理が重たい時)かつ n=3

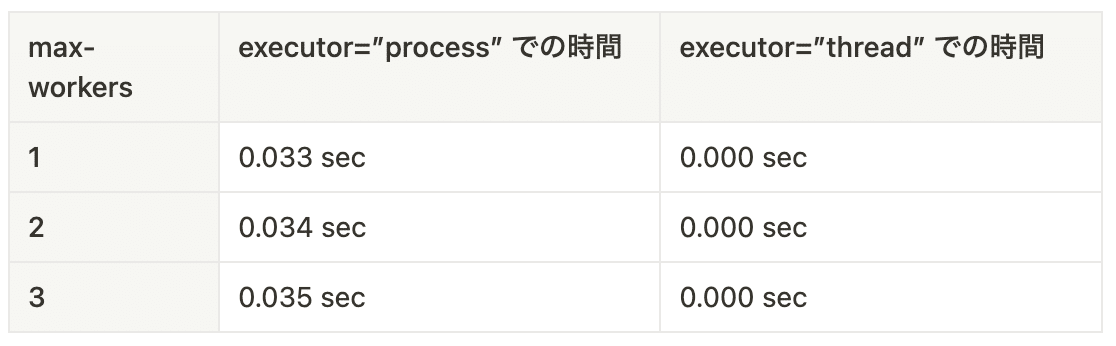
x=2, y=0 の時(CPU処理が軽い時)かつ n=3
考察
CPU 処理が重たい時について見てみます。
プロセスを用いたケースでは並列度が上がるにしたがって処理時間が短くなります。今回のケースでは、1 回の処理が 11〜12 秒程度程度かかっているように見えます。この時 max-workers=1 の時は、順番に処理されるため 3 倍程度の時間が、 max-workers=2 の時は、初めに 2 並列で処理し、その後 3 つ目処理するため 2 倍程度の時間が、max-workers=3 の時は 3 並列で処理するため 1 倍程度の時間となっており、概ね想定通りの時間となっています。対して、スレッドを用いたケースでは、並列数を上げても全く処理時間が変化していません。これは、はじめに述べた GIL の影響が如実に出ているものと考えられます。
次に、CPU 処理が軽いときについて見てみます。
このとき、プロセスを用いたケースでは、30 ms台前半の時間がかかっているのに対し、スレッドでは 1 ms 未満で処理できています。これは、プロセスを超える場合、リソースを共有していないがゆえに様々なオーバーヘッドが発生するため、そのオーバヘッドが計測されていると考えられます。
パターン2: 大きなデータの受け渡し
次に大きなデータを Executor に受け渡すケースを考えます。以下のコードでは、 n 回 0..x-1 が入った配列から y 要素目を取り出します。
コード
import time
from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from typing import List
def pick(x: List[int], y: int) -> int:
return x[y]
def _main() -> None:
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
parser.add_argument("-x", type=int, default=2)
parser.add_argument("-y", type=int, default=30)
parser.add_argument("-n", type=int, default=3)
parser.add_argument("--max-workers", type=int, default=5)
parser.add_argument("--executor", choices=["process", "thread"], default="process")
args = parser.parse_args()
assert args.x > args.y, "x must be greater than y"
x_list: List[int] = [[i for i in range(args.x)]] * args.n
y_list: List[int] = [args.y] * args.n
max_workers: int = args.max_workers
executor_class = (
ProcessPoolExecutor if args.executor == "process" else ThreadPoolExecutor
)
with executor_class(max_workers=max_workers) as executor:
start = time.time()
futures = executor.map(pick, x_list, y_list)
for res in futures:
print(res)
end = time.time()
print(f"elapsed: {end - start:.6f} sec")
if __name__ == "__main__":
_main()結果
x=100000000, y=1, n=3 の時

考察
プロセスを利用すると非常に処理が重たくなる傾向が見て取れます。これは、異なるプロセスではメモリが共有されていないために、 map に渡されたデータをシリアライズ/デシリアライズ する必要性があるためと考えられます。
パターン3: グローバル変数
次にグローバル変数の動作について確認するために以下のコードを利用します。ジョブサブミット後、グローバル変数を書き換えます。ジョブは一定時間 sleep した後に、グローバル変数を返します。
コード
import time
from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from typing import List
global_variable = 0
def pick(sleep_time: float) -> int:
time.sleep(sleep_time)
return global_variable
def _main() -> None:
global global_variable
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
parser.add_argument("--max-workers", type=int, default=5)
parser.add_argument("--executor", choices=["process", "thread"], default="process")
args = parser.parse_args()
sleep_time = 0.1
max_workers: int = args.max_workers
executor_class = (
ProcessPoolExecutor if args.executor == "process" else ThreadPoolExecutor
)
with executor_class(max_workers=max_workers) as executor:
futures = executor.map(pick, [sleep_time] * 1)
global_variable = 1
for res in futures:
print(res)
futures = executor.map(pick, [sleep_time] * 2)
global_variable = 2
for res in futures:
print(res)
futures = executor.map(pick, [sleep_time] * 3)
global_variable = 3
for res in futures:
print(res)
if __name__ == "__main__":
_main()結果

考察
スレッドではメモリが共有されているが、プロセスではそうでなく ProcessPoolExecutor 作成時の値が保持されることが観察されたと考えられます。
実測のまとめ
上記の結果を総計すると以下のような使い分けとなると考えられます。
プロセスによる並列処理の使い所
以下の条件を全て満たすとき
GIL が解放されないような処理を行うとき
大量のデータを受け渡す場合は、そのデータが ProcessPoolExecutor の作成前にグローバル変数に配置されている場合
ただし、Python 3.14 以降では Unix 系のデフォルトの開始方法が変更されるので、 ProcessPoolExecutor 自体の作成に時間がかかるようになるかも知れません。
スレッドによる並列処理の使い所
以下の条件を満たすとき
GIL が解放される処理を行うとき
具体的には
GIL を解放するプラグインの呼び出し
IO 処理で、通信速度自体はボトルネックにはならないケース
→ LLM の通信の処理は通信速度は関係ないのでスレッドを使えば十分
GIL が解放されないケースでも、受け渡しデータが大量の場合は ProcessPoolExecutor に勝ちうるので、計測をするべき。
asyncio モジュール
async/await は近年の多くのプログラミング言語において取り入れられている、プログラミング構文です。非同期プログラミングを同期なコードと同等に記述できるメリットがあります。これを Python で実現するランタイムを実装しているものが asyncio モジュールです。ファイルの操作や HTTP の操作は含まれておりませんので、 aiofiles や httpx も追加で利用することになると思われます。
Python で async/await を利用するメリット/デメリット
利用するメリットとデメリットについて、筆者の考えに基づいてまとめると以下のようになります。
メリット
流行りに乗れる処理のキャンセルが実現できる
シングルスレッドでもマルチタスクが実現できる
デメリット
構文が異なる
一旦使い始めたら、使わないコードに戻すのが面倒
asyncio のことはじめ
最も簡単な例として、以下の同期で sleep するコードを考えます。
import time
def main():
print('Hello ...')
time.sleep(1)
print('... World!')
main()これを asyncio で書き換えると以下のようになります。
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
asyncio.run(main())基本的に、async def にて関数を定義し、その内部で他の async な関数を呼ぶ際は、 await 関数名(...) とすることで、同期コードのように記述できます。await は指定された awaitable オブジェクトが実行を完了するまで動作を停止し、実行を完了するとその値を返します。
処理の並行化
上記のコードでは特に面白みがないので、並行化を行います。以下のような、 10 ms と 20 ms で sleep しつつ 5 回 カウントを行うような同期サンプルコードを考えます。
import time
import threading
def sleep_print(wait: float, times: int) -> None:
for i in range(times):
time.sleep(wait)
print(f"Print {wait=}, {i=}")
def main():
th1 = threading.Thread(target=sleep_print, args=(0.01, 5)); th1.start()
th2 = threading.Thread(target=sleep_print, args=(0.02, 5)); th2.start()
th1.join()
th2.join()
main()これを asyncio で書き換えると以下のようになります。
import asyncio
async def sleep_print(wait: float, times: int) -> None:
for i in range(times):
await asyncio.sleep(wait)
print(f"Print {wait=}, {i=}")
async def main():
task1 = asyncio.create_task(sleep_print(0.01, 5))
task2 = asyncio.create_task(sleep_print(0.02, 5))
await task1
await task2
asyncio.run(main())同期の世界の threading.Thread に対応する存在として、 asyncio では asyncio.Task というクラスがあります。これは asyncio.create_task 関数を用いることで生成できます。 threading.Thread では start 関数を呼び出す必要がありますが、 asyncio.create_task では不要です。
他の言語を利用している方に対する注意点
JavaScript では、 async function で定義した関数を呼び出した返り値を await しなくても、呼び出し先の処理が実行されますが、 Python では await するか asyncio.create_task の引数として渡す必要があります。
並行化した処理を同時に待つ
*PoolExecutor の map 関数のような、関数の return された値を集める関数として asyncio.gather があります。 パターン2 のようなコードは以下のように書けます。
import asyncio
import time
from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from typing import List
async def pick(x: List[int], y: int) -> int:
return x[y]
async def _main() -> None:
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
parser.add_argument("-x", type=int, default=2)
parser.add_argument("-y", type=int, default=30)
parser.add_argument("-n", type=int, default=3)
args = parser.parse_args()
assert args.x > args.y, "x must be greater than y"
x_list: List[int] = [[i for i in range(args.x)]] * args.n
y_list: List[int] = [args.y] * args.n
start = time.time()
results = await asyncio.gather(*(pick(x, y) for x, y in zip(x_list, y_list)))
for res in results:
print(res)
end = time.time()
print(f"elapsed: {end - start:.6f} sec")
if __name__ == "__main__":
asyncio.run(_main())また、複数の Task のうち、1 つの処理が終わったタイミングまで待つなどの細かい制御を行える asyncio.wait が存在しています。
キャンセル処理
asyncio.Task には cancel という関数があり、この関数を呼び出すと実行中のタスクを途中でキャンセルすることができます。
キャンセルされた場合、内部で実行中の async def で実行された関数においては、 await 式が asyncio.CancelledError 例外を送出します。この例外は、Exception は継承しておらず、 BaseException を継承しています。
例外が送出されるため、 asyncio.Semaphore などの acquire と release のような呼び出し回数の対応を取る必要性のある処理は、 try-finally を利用するか、 async with 構文を利用する必要があります。
簡単な例として以下のようなコードを見てみます。このコードでは、asyncio.Semaphore で同時に 2並行の処理に制限しつつ、冪乗を 1 秒かけて計算するプログラムとなっています。計算を始めたタイミングと、計算し終わるかキャンセルされたタイミングで、ステータスと時刻を表示します。0〜9 の 10つ分処理を並行に開始し、3.5s でタイムアウトさせます。
import asyncio
import time
SEMAPHORE = asyncio.Semaphore(2)
async def calc_square(x: int) -> int:
try:
async with SEMAPHORE:
# Simulate a long running task
print(f"Calculating square of {x}, time: {time.time()}")
ret = x * x
await asyncio.sleep(1)
print(f"Calculated square of {x}, time: {time.time()}")
return ret
except asyncio.CancelledError:
print(f"Cancelled square of {x}, time: {time.time()}")
raise
async def _main() -> None:
try:
calc_results = await asyncio.wait_for(
asyncio.gather(*[calc_square(i) for i in range(10)]), timeout=3.5
)
print(calc_results)
except asyncio.TimeoutError:
print("Timed out")
if __name__ == "__main__":
asyncio.run(_main())実行すると以下のような出力が得られます。
Calculating square of 0, time: 1705246528.0706766
Calculating square of 1, time: 1705246528.0706942
Calculated square of 0, time: 1705246529.07582
Calculated square of 1, time: 1705246529.0758388
Calculating square of 2, time: 1705246529.0758498
Calculating square of 3, time: 1705246529.07587
Calculated square of 2, time: 1705246530.0809927
Calculated square of 3, time: 1705246530.0810106
Calculating square of 4, time: 1705246530.0810215
Calculating square of 5, time: 1705246530.0810397
Calculated square of 4, time: 1705246531.0861235
Calculated square of 5, time: 1705246531.0861347
Calculating square of 6, time: 1705246531.0861447
Calculating square of 7, time: 1705246531.0861568
Cancelled square of 6, time: 1705246531.5736876
Cancelled square of 7, time: 1705246531.5736966
Cancelled square of 8, time: 1705246531.5737019
Cancelled square of 9, time: 1705246531.57370571秒で 2つ処理が行えるため、0〜5 の 6つ分は計算が計算が完了するが、6, 7 は計算中に Cancel され、8, 9 は開始すらされない様子が観察できます。
参考文献
以上、簡単に asyncio について解説しました。
asyncio のみでプログラムを書く場合、以下のページのドキュメントが非常に良くまとめられているため、初めに見る資料として非常におすすめです。
また、同期側のコードと相互に連携して asyncio を利用する場合、以下のドキュメントの内「コールバックのスケジューリング」「スレッドプール/プロセスプール」「タスクとフューチャー」あたりをご参照されると良いと思われます。
ThreadPoolExecutor と asyncio の比較
パターン1 で行ったものを asyncio で実装し直し速度を比較します。実装し直したものは、以下のようになります。
import asyncio
import time
from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from typing import List, Optional
SEMAPHORE: Optional[asyncio.Semaphore] = None
async def too_slow_function(x: int, y: int) -> int:
# x^(2^y) を計算
for _ in range(y):
x *= x
return x
async def too_slow_function2(x: int, y: int) -> int:
async with SEMAPHORE:
# 1 を計算
return (await too_slow_function(x, y)) // (await too_slow_function(x, y))
async def _main() -> None:
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
parser.add_argument("-x", type=int, default=2)
parser.add_argument("-y", type=int, default=30)
parser.add_argument("-n", type=int, default=3)
parser.add_argument("--max-workers", type=int, default=5)
args = parser.parse_args()
x_list: List[int] = [args.x] * args.n
y_list: List[int] = [args.y] * args.n
max_workers: int = args.max_workers
global SEMAPHORE
SEMAPHORE = asyncio.Semaphore(max_workers)
start = time.time()
results = await asyncio.gather(
*[too_slow_function2(x, y) for x, y in zip(x_list, y_list)]
)
end = time.time()
for res in results:
print(res)
end = time.time()
print(f"elapsed: {end - start:.3f} sec")
if __name__ == "__main__":
asyncio.run(_main())実行結果
x=2, y=30 の時(CPU処理が重たい時)かつ、 n=3
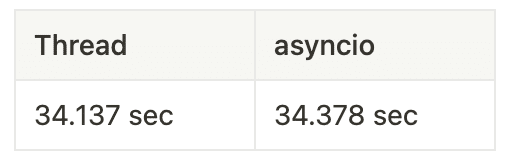
x=2, y=0 の時(1タスクの処理が軽い時)かつ、 n=3000000 (print は省略した)

結果考察
asyncio はシングルスレッド動作であるのにも関わらず、CPU処理メインであれば)ThreadPoolExecutor と概ね同等の性能を示す
細かいタスク実行となると、 Thread の同期コストが無視できなくなり、ワーカーの増加で性能が逆に劣化し、シングルスレッドの asyncio の方が性能が良くなる
GIL の無効化の効果
Python 3.13a5 以降のリリースでは、コンパイル時に --disable-gil option を指定することにより、特定の条件下で GIL の無効化を行えるようになっています。
本章ではこれを有効化し、パターン1 のケースで ThreadPoolExecutor の処理時間が GIL の有効無効でどの程度変わるかをみます。
Python 3.13.0a5 のビルド
Python のビルドの依存については、pyenv のこちらがよくまとまっておりますので、それらを事前にインストールを行います。
その後、以下のコマンドでビルドが行えます。M1 Mac では、カレントディレクトリ以下に python.exe が生成されました。
git clone -b v3.13.0a5 --depth 1 git@github.com:python/cpython.git
cd cpython
./configure --enable-optimizations --disable-gil
make -j$(nproc)ベンチマーク
上のパターン1 のケースで再測定を行います。この際、 ./python.exe の引数に -X gil=0 を付けたケースと比較をします。-X gil=0 を付けると GIL が無効となります。
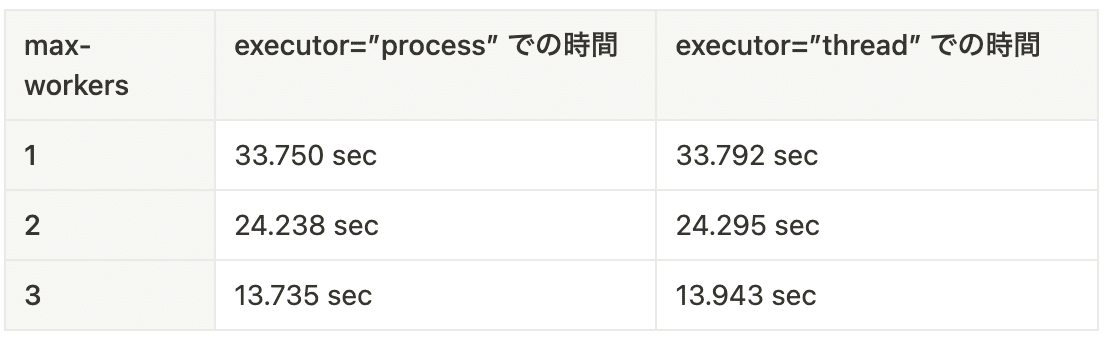
x=2, y=30 の時(CPU処理が重たい時)かつ n=3
-X gil=0 なし

-X gil=0 あり
結果考察
ベンチマークのを見ても明らかの通り、GIL を無効化するとスレッドのワーカー数を増やした際も処理時間が減少しています。GIL が非常に悪影響を与えていることが明確になったように思います。
今後の展望
処理速度のみを求めた multiprocessing の利用は、将来的に必要性が薄くなりそうだと思われます。処理を真に並列して実行したいためだけにプロセスを分離する必要がなくなるのは、処理間のデータの共有の観点からメリットが大きいのでかなり期待をしています。ただ、GIL 無効化するとエラーが発生することもあり、(アルファ版であることから当たり前ではありますが、)まだプロダクションに組み込むには早いとの印象を受けました。今後の安定化に期待したいところです。
interpreters モジュールについて
Python 3.12 及び 3.13 から、一つのプロセスに対して、異なる GIL を持つ複数の Python のインタープリターを実行することが可能となっています。これを利用することによって、単一プロセスで Python コードを並行実行することができます。
ただし、https://peps.python.org/pep-0734/#interpreter-isolation に書かれている通り、ごく一部のデータを除いてデータの共有はなされないため、multiprocessing による分離に近いものとなっています。ただし、memoryview を経由したバッファプロトコルによるメモリの共有が可能であるため、シェアードメモリを利用するよりも容易にデータ共有が行える点は特筆するべき点に思います。本記事では詳細は割愛します。
おわりに
本記事では、以下 3 点を行いました。
Python におけるスレッドとプロセスの速度比較
asyncio も含めた速度比較
将来的な機能である GIL の無効化での速度比較
これらの知識を用いることによって、Python という言語を利用しながらも、機械学習のプログラムにおいて計算機リソースを余すことなく活用でき、モデルの学習や、API の応答速度の高速化などを行うことができます。
ただ、この記事において触れていないものとして、プロセス/インタープリタ間のメモリ共有機能や、GPU メモリ利用時のスレッドとプロセスの挙動の差、GPU は CPU と非同期に実行/データ転送ができる点など、実際のプログラムにおいて考慮するべき事項はまだたくさんあります。これらについては、今後の記事に譲らさせていただき、今回はここで筆を置かせていたきます。
―INFORMATION―
PKSHA Technology では、共に働く仲間を募集しています。このような技術に興味を持っていただけた場合は、採用サイトや Wantedly から応募やカジュアル面談が可能ですので、是非ご覧ください!
▼ 26 新卒:アルゴリズムエンジニア(データサイエンティスト)

▼ 中途採用:アルゴリズムエンジニア(データサイエンティスト)

▼ カジュアル面談も受け付けています:Wantedly はこちら